【技术深度】当合成数据挣脱"辅助工具"枷锁:大模型垂直领域训练范式的根本性转向
2024年初,我第一次在内部技术评审会上提出"合成数据可能优于RAG"的假设时,会议室里的沉默持续了整整三十秒。
被行业共识掩盖的技术真相
彼时的大模型行业,RAG已被奉为垂直领域落地的"标准答案"。金融、医疗、法律等高精准度场景的从业者,几乎众口一词地认定:合成数据不过是RAG的配角,永远无法独当一面。这种判断并非空穴来风——此前数年的大量实验证明,单纯依赖合成问答对或合成文档训练的模型,性能提升总是快速触顶,在对照测试中往往落后成熟RAG方案4至6个百分点。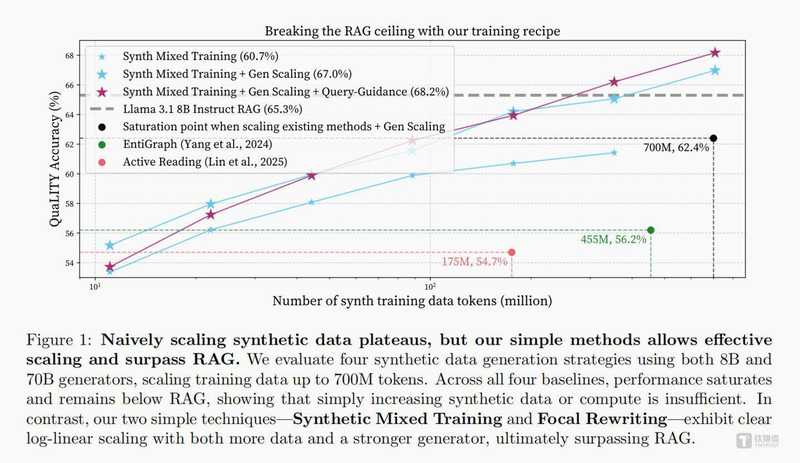
我和团队同样深陷这一困境。在长达数月的迭代中,我们尝试过更换更强的生成模型、堆砌更大规模的数据集、甚至引入多模态增强策略,但每次测试结果都指向同一个结论:合成数据存在无法突破的性能天花板。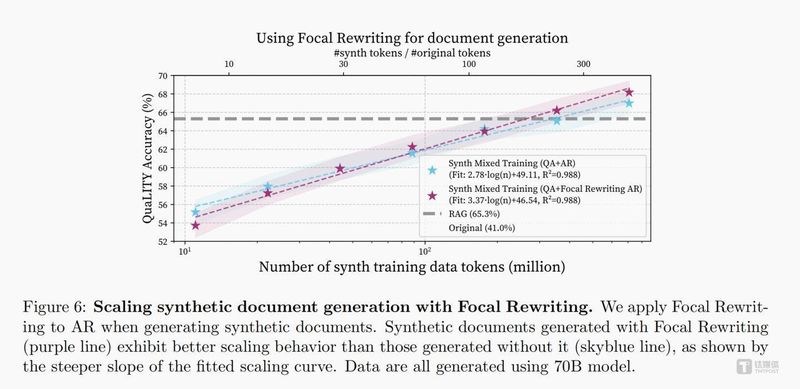
关键发现:单一数据类型的结构性缺陷
转折点出现在对失败案例的深度复盘。我们发现,之前的训练策略从根子上就走进了死胡同。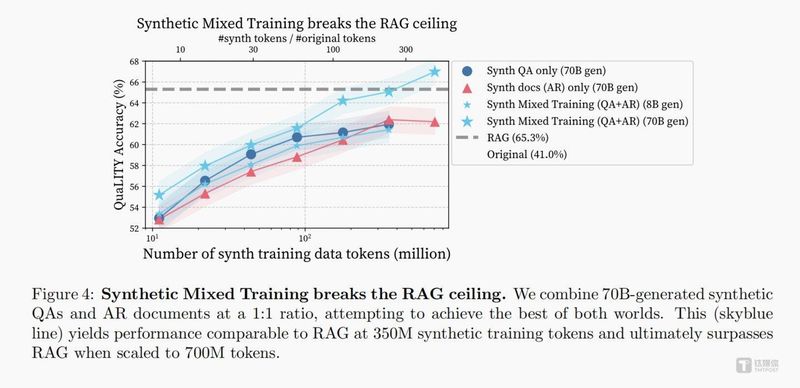
合成问答对的优势在于锤炼模型的推理逻辑与知识调用能力,但它无法让模型真正掌握专业领域的细节知识。合成文档能够系统性地灌输垂直领域干货,却难以教会模型灵活运用这些知识。两种数据类型单打独斗,模型只能习得片面能力,无法实现知识与能力的融合——这才是性能无法突破的真正原因。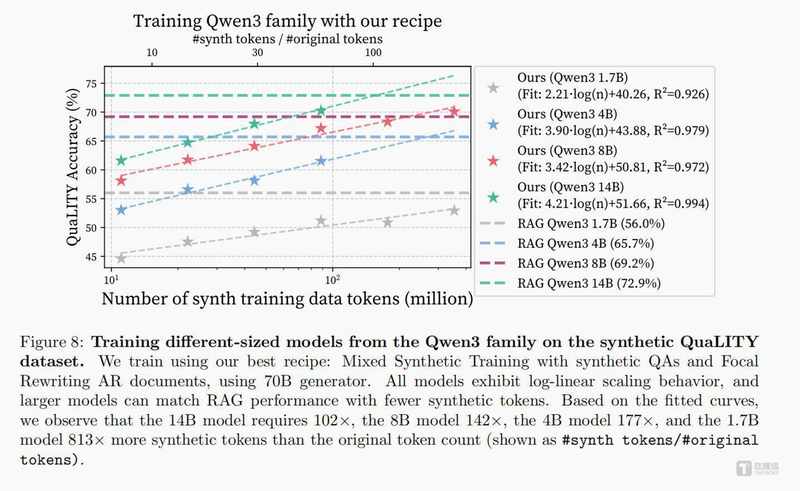
合成混合训练:数据配比的艺术
找准症结后,解决方案反而清晰起来。既然单一数据类型存在结构性缺陷,那就让两种数据类型协同作战。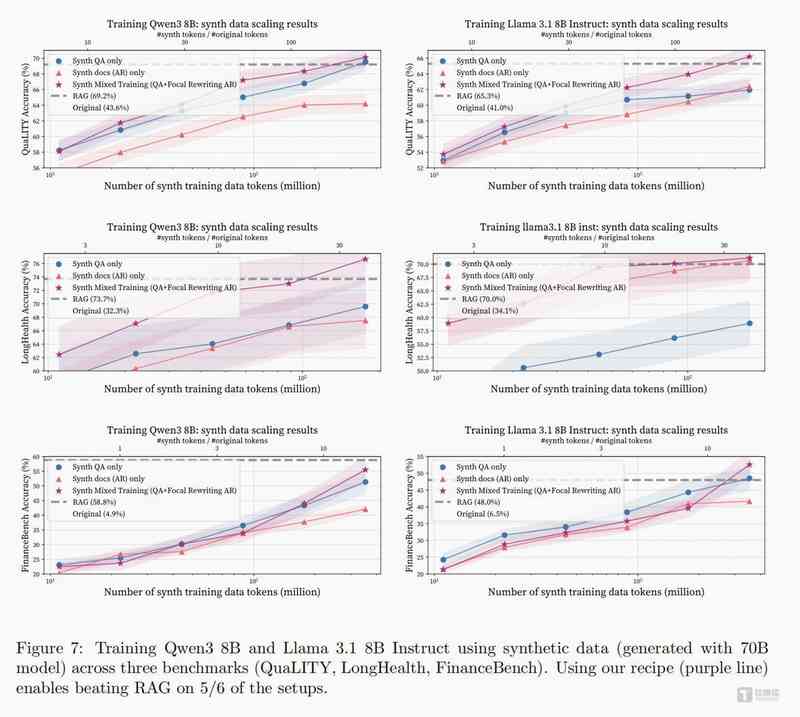
我们将合成问答对与合成文档按1:1比例混合,共同用于模型微调训练。两类数据形成完美互补:问答对负责锤炼推理能力与解题思路,文档负责灌输专业知识与领域常识。实验结果证实了这一策略的有效性——采用合成混合训练(SMT)的模型,在长文本理解(QuALITY)、医疗专业问答(LongHealth)、金融分析研判(FinanceBench)三大权威测试场景中,均实现对传统RAG方案的性能超越,在QuaLITY数据集上的领先幅度达到4.4%。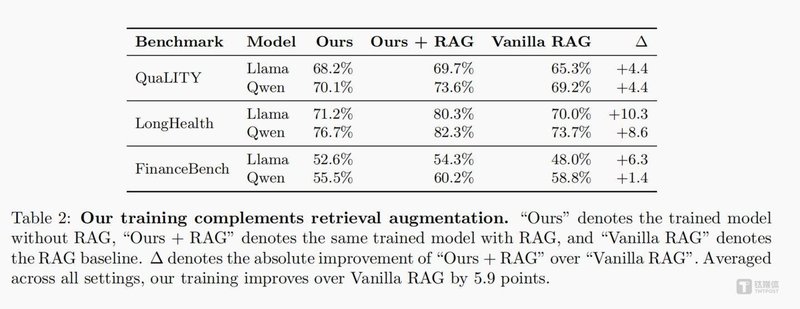
聚焦重写:训练效率的二次优化
数据配比问题解决后,团队进一步关注训练效率。为避免模型将精力耗费在冗余、重复的无效信息上,我们推出了配套技术——聚焦重写(FocalRewriting)。这项技术的核心逻辑是引导生成的文档紧扣关键问题展开,剔除无关内容,让模型集中吸收高价值知识点。实验数据显示,配合聚焦重写技术后,模型的学习效率显著提升。
更具实用价值的是,将SMT训练后的模型与RAG结合使用,性能可在原有基础上再提升9.1%,实现双重增效。这意味着SMT并非要取代RAG,而是与之形成互补,为企业提供了更灵活的技术组合选项。
轻量化落地的产业启示
对于产业界而言,SMT最值得关注的价值在于对中小参数模型的友好性。8B及以下的轻量模型,仅需少量高质量合成数据,就能达到甚至超越传统RAG的效果,无需堆砌海量算力,无需搭建复杂的检索系统。这意味着中小厂商也能轻松布局垂直领域AI,大幅降低了行业准入门槛。
从技术演进的角度看,SMT的出现在一定程度上打破了"唯参数论、唯算力论"的行业惯性。它用实验数据证明:精细化的数据处理与科学的训练方式,远比盲目扩张硬件更具价值。对于正在探索大模型落地的技术团队而言,这或许是一个值得重新审视合成数据战略的关键信号。